SCIENCE
In this section we focus on life science, physical science, and social science. You can click on these links to read more information on these topics. (Links to the other two topics will be provided later)
The pages of the above topics contain information of more technical nature. On this page we present books/articles for the general public on several ground-breaking areas of science.
(1) News about black holes, dark matter, etc. pop up on newspapers occasionally. They are based on Einstein’s theory of relativity. What is relativity? We can read from the most authoritative source: Einstein himself. Below is a portrait of Einstein:

Below are one book and one chapter of a book written by Einstein.
(a) Relativity – the Special and General Theory. According to the Preface: “The present book is intended, as far as possible, to give an exact insight into the theory of Relativity to those reader who, from a general scientific and philosophical point of view, are interested in the theory, but who are not conversant with the mathematical apparatus of theoretical physics.”

(b) The Problem of Space, Ether, and the Field in Physics. It is one chapter from Einstein’s book, "The World As I See It." It is relatively short, only 15 pages long.

For those who are curious about Einstein's ground-breaking paper introducing the world to the concept of relativity, you can read an English translation of his 1905 paper: "On the Electrodynamics of Moving Bodies". The first four pages should be understandable for people with little mathematics knowledge.

(2) We use computers, mobile phones, etc. everyday. All these impressive products are based on a branch of physics known as quantum physics. We present two publications:
(a) I Don’t Understand Quantum Physics. It is written by Douglas Ross, FRS, Emeritus Professor of Physics of University of Southampton. According to the Foreword: “This article is designed to describe (but not explain) the mysteries of Quantum Physics to the interested lay person. I assume that the reader has studied and absorbed Physics and Mathematics at normal High School level, but not at any further level.”

(b) Quantum Physics: Some Basics. This article is written by P. C. E. Stamp, a Professor at the University of British Columbia. Practically no mathematical formula is used. It is also relatively short, 24 pages.

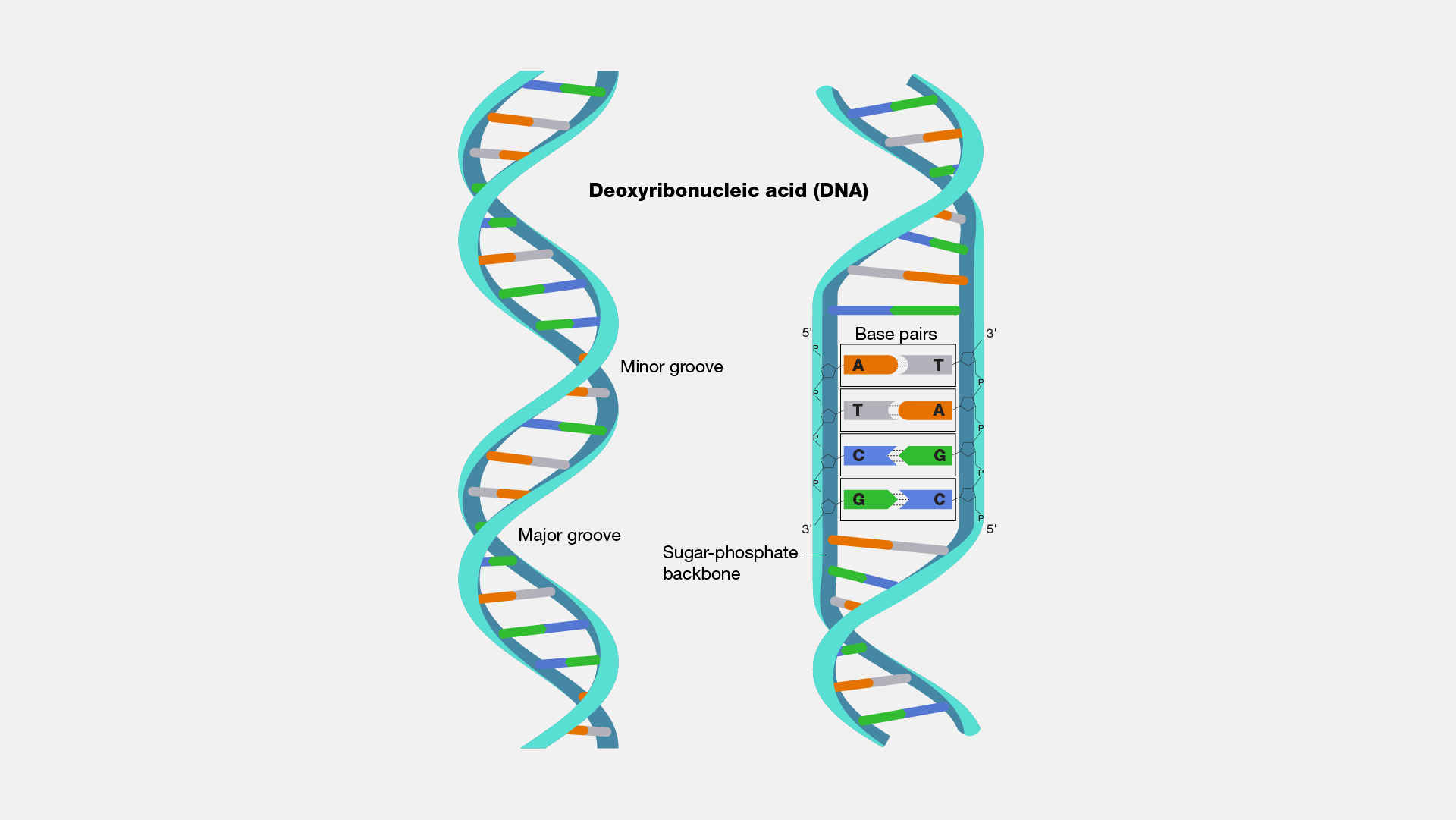
(3) Everyone have heard of DNA. Its discovery changed our understanding of biology. The structure of DNA was described in a 1953 seminal paper written by Watson and Crick (James Watson was 25 years old at that time). Surprisingly, it is a short paper and not difficult to read. This is a link to their paper with annotations: A Structure for Deoxyribose Nucleic Acid (note: this is a link to an outside website).

Below is an illustration of a DNA structure:
(4) The word “ego” now becomes a household word and the person who coined the word, Sigmund Freud, is also famous. Let us read his book “The Ego and the Id.” The book is about 80 pages long (without counting the cover, translator’s note, etc.) and should be understandable by the general public.

(5) In 1859 Charles Darwin published a book titled “On the Origin of Species by Means of Natural Selection.” This book is considered the foundation of evolutionary biology. On the other hand, this book aroused widespread debates not only in biology but also in social, philosophical, and religious circles.
(a) The book is about 400 pages long. We extracted the last chapter of this book, “Recapitulation and Conclusion,” which has only 24 pages, for our visitors’ perusal. For those who want to read the full book, you can download it here.

(b) Very few famous scientists write an autobiography. Charles Darwin wrote a short one (62 pages). His son, Francis Darwin, published it. You can read his autobiography here.

(c) One of the most important contributions to the formulation of Darwin's theory was his 1831-1836 journey on HMS Beagle. Below is a map showing Darwin's journey:
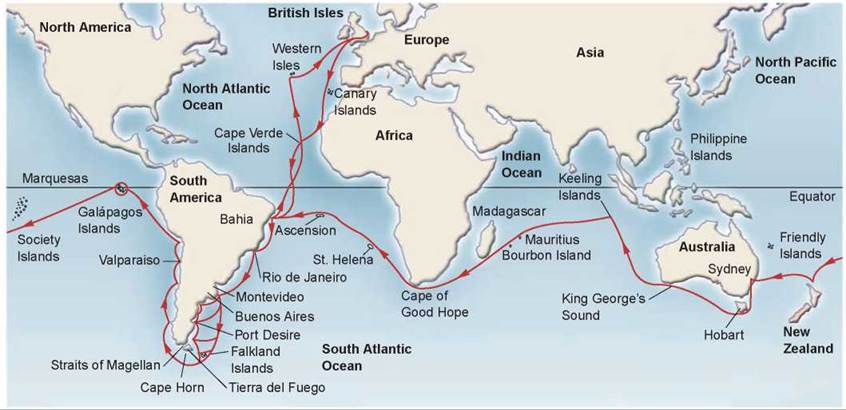
One of the stops of HMS Beagle was the Galápagos Islands, which is on the equator about 906 km (563 miles) west of South America (shown on the above map). Darwin collected samples there, including a collection of birds later called “Darwin’s finches,” in honor of him. They are thought to have evolved from a single finch species that came to the islands more than a million years ago. The most important differences between species are in the size and shape of their beaks, which are highly adapted to different food sources. More information about Darwin’s finches can be found on the Galápagos Islands page.
As can be seen from the above map, most of Darwin's journey was in the southern hemisphere. Darwin wrote a book about his journey after returning to England. The book is a lively and charming account of his travels. If you are interested in learning more about the southern hemisphere (especially the condition of the hemisphere about 200 years ago), you should read his book: The voyage of the Beagle (file size: about 12 MB).

(6) Artificial Intelligence
Artificial intelligence is a broad discipline. We will discuss two recent developments that some people might find interesting: ChatGPT and conjecture generator (also called the Ramanujan machine).
(a) ChatGPT
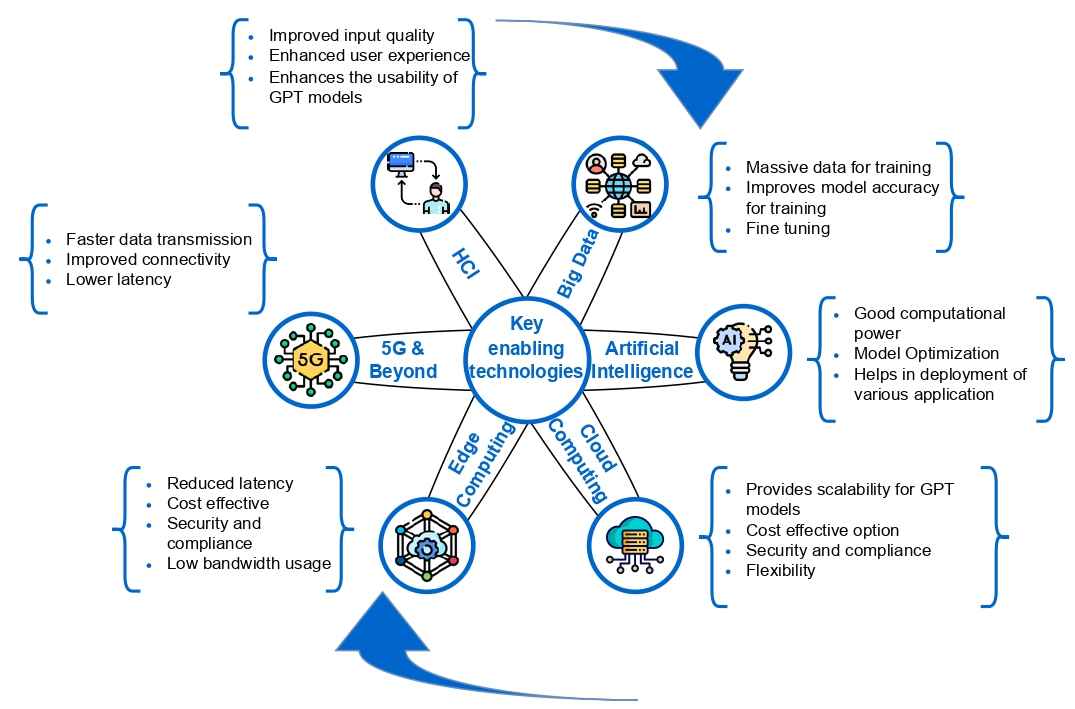
In November 2022, artificial intelligence landed on the front page of major newspapers after a company named OpenAI launched its ChatGPT service free to the public. By January 2023, ChatGPT reached over 100 million users. A Pew Research poll conducted in March 2023 found that 14% of American adults had tried ChatGPT. ChatGPT makes use of a branch of artificial intelligence and other technologies. Below is a drawing showing its enabling technologies:
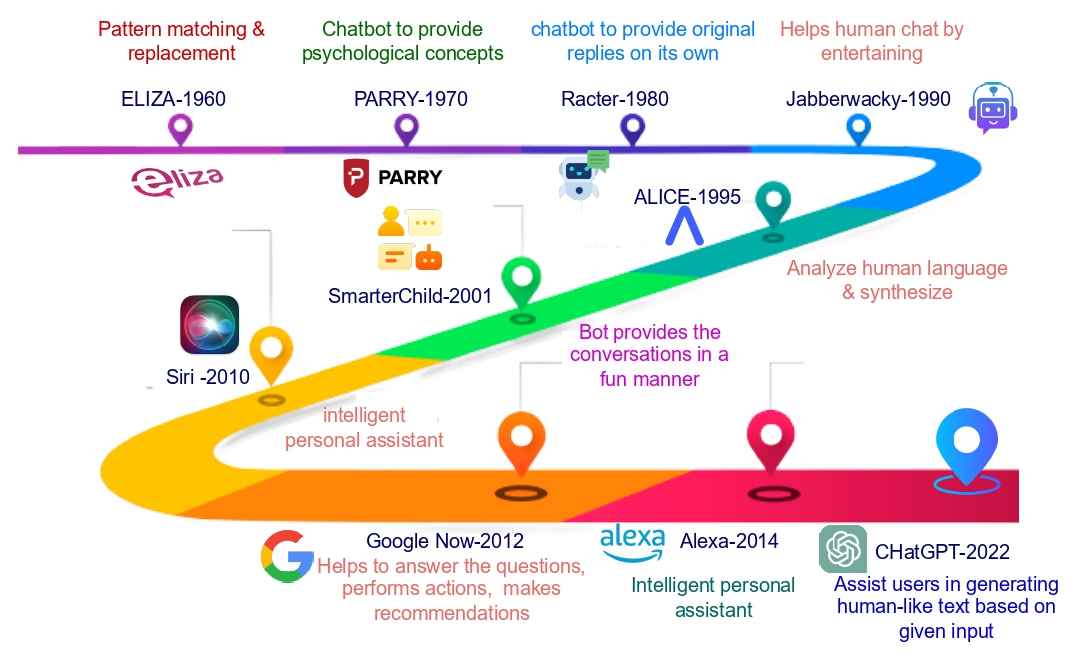
ChatGPT does not emerge overnight. It is a result of a long line of research and products. Below is a drawing showing the evolution of related technology and products:
What is the technology behind ChatGPT? Not surprisingly, it is complicated. We found a readable introduction to the history and technology of this branch of artificial intelligence written by more than 10 scientists. The lead author is Gokul Yenduri of the Vellore Institute of Technology in India. Other authors are associated with universities in Canada, mainland China, Hong Kong, Lebanon, Norway, and Taiwan.

The paper is 40 pages long. Below are relevant portions of the paper "GPT (Generative Pre-trained Transformer) – A Comprehensive Review on Enabling Technologies, Potential Applications, Emerging Challenges, and Future Directions". The paper uses acronyms extensively (close to 30). The following are those used below:
AI: Artificial Intelligence
API: Application Programming Interface (Defined by Wikipedia as: it is a way for two or more computer programs to communicate with each other; it is a type of software interface, offering a service to other pieces of software.)
ML: Machine Learning
NLP: Natural Language Processing (Defined by Wikipedia as: It is an interdisciplinary subfield of linguistics, computer science, and artificial intelligence concerned with the interactions between computers and human language, in particular how to program computers to process and analyze large amounts of natural language data.)
TL: Transfer Learning (Defined by Wikipedia as: it is a technique in machine learning in which knowledge learned from a task is re-used in order to boost performance on a related task.)
"GPT models have evolved through multiple changes and breakthroughs in NLP technology. These are some significant turning points in the growth of the GPT model: Before GPT, NLP models have been trained on large amounts of annotated data that is related to a specific task. This had a significant drawback because it was difficult to access the quantity of labelled data required to train the model precisely. The NLP models were unable to complete tasks outside of their training set since they were restricted to a particluar set of data. To get around these restrictions, OpenAI offered a Generative Language Model called GPT-1 that was created using unlabeled data and then given to users to fine-tune to carry out subsequent tasks like sentiment analysis, categorization, and question-answering. This indicates that the model attempts to produce an appropriate response based on input and that the data used to train the model is not labelled. Fig. 2 shows the timeline of the evolution of several pre-trained models from Eliza, which was created in 1960, to the more current 2022-ChatGPT.
GPT-1 was the first ever model that could read the text and respond to queries. OpenAI released GPT-1 in 2018. GPT-1 was a major move forward in AI development because it enabled computers to comprehend textual material in a more natural manner than before. This generative language model was able to learn a wide variety of connections and gain immense knowledge on a varied corpus of contiguous text and lengthy stretches. This happened after being trained on a huge BooksCorpus dataset. In terms of design, GPT-1 employs a 12-layer decoder architecture transformer with a self-attention system for training. GPT-1’s capacity to execute zero-shot performance on different tasks was one of its major success as a result of its pre-training. This ability demonstrated that generative language modelling can be used to generalize the model when combined with a successful pretraining idea. With TL as its foundation, GPT models evolved into a potent tool for performing NLP tasks with minimal fine-tuning. It paved the way for other models to progress even more in generative pre-training using larger datasets and parameters.
To create a better language model later in 2019, OpenAI created a GPT-2 using a bigger dataset and more parameters. The model design and execution of GPT-2 are some of the key advancements. With 1.5 billion parameters, it has 10 times the size of GPT-1 (117 million parameters), and it has 10 times as many parameters and data. By using only the raw text as input and utilizing little to no training examples, it is effective in terms of resolving various language tasks related to translation, summarization, etc. Evaluation of GPT-2 on various downstream task datasets revealed that it excelled by substantially increasing accuracy in recognizing long-distance relationships and predicting sentences. The most recent iteration of the GPT model is GPT-3. It is a sizable language prediction and production model created by OpenAI that can produce lengthy passages of the source text.
GPT-3 eventually emerged as OpenAI’s ground-breaking AI language software. Simply put, it is a piece of software that can create lines on its own that are so distinctive they almost sound like they were written by a human. The GPT-3 program is presently accessible with limited access via a cloud-based API, and access is required to investigate the utility. Since its debut, it has produced several interesting apps. Its capacity, which is about 175 billion parameters big and 100 times larger than GPT-2, is a key advantage. It is taught using a corpus of 500 billion words called ”Common Crawl” that was gathered from a sizable content archive and the internet. Its other noteworthy and unexpected capability is its ability to carry out basic mathematical operations, write bits of code, and carry out clever tasks. As a result, NLP models can help businesses by responding more quickly to requests and accurately keeping best practices while minimizing human mistakes. Due to its intricacy and size, many academics and writers have referred to it as the ultimate black-box AI method. Due to the high cost and inconvenience of performing inference, as well as the billion-parameter size that makes it resource-intensive, it is difficult to put into practice in jobs.
GPT-4 was named as the successor of GPT-3. In the meantime, several AI models built on GPT-3.5, an updated version of GPT-3, have been surreptitiously released by OpenAI. GPT-3.5 was trained on a mixture of text and code. From the vast amounts of data collected from the web, which includes tens and thousand of Wikipedia entries, social media posts, and news items, GPT 3.5 learned the relations between words, sentences, and various components. It was utilized by OpenAI to develop several systems that have been tailored to complete particular jobs. It collected vast amounts of data from the web, including tens of thousands of Wikipedia entries, posts on social media, and news items, and used that information to learn the relationships between sentences, words, and word components.
The latest version of the GPT model by OpenAI is GPT-4 which is a multimodal big language model. It was launched on March 14, 2023, and is now accessible to the general public through ChatGPT Plus in a constrained capacity. A waitlist is required to gain access to the business API. Using both public data and ”data licensed from third-party providers,” GPT-4 was pre-trained to anticipate the next coin as a transformer. It was then adjusted with reinforcement learning based on input from humans and AI for human alignment and policy conformance. In comparison to GPT-3, which had context windows of only 4096 and 2049 tokens, respectively, the group created two variants of GPT-4 with context windows of 8192 and 32768 tokens.
GPT model’s architecture
GPT models are based on neural networks that are used for NLP tasks, such as language modelling, text classification, and text generation.
The GPT model’s architecture is based on the transformer model. The Transformer model uses self-attention mechanisms to process input sequences of variable length, making it well-suited for NLP tasks. GPT simplifies the architecture by substituting encoder-decoder blocks with decoder blocks. GPT model takes the transformer model and pre-trains it on large amounts of text data using unsupervised learning techniques. The pre-training process involves predicting the next word in a sequence given the previous words, a task known as language modelling. This pre-training process enables the model to learn representations of natural language that can be fine-tuned for specific downstream tasks. The following are the components of the GPT architecture.
• Input Embedding layer: The embedding layer maps the input tokens (e.g., words or subwords) to continuous vector representations, which can be processed by the transformer blocks.
• Positional encoding: Since the transformer blocks do not have any notion of order or position, positional encoding is added to the input embeddings to provide information about the relative position of tokens. Masking: In some cases, masking may be necessary to mask certain input tokens (e.g., in language modelling tasks, the model should only use tokens that come before the target token). Transformer blocks: GPT models are based on the transformer architecture. It is designed for NLP tasks and has been widely used in applications such as machine translation, text classification, and text generation. Transformers allow the model to focus on different areas of the input while processing.
• Linear and Softmax Functions: In the GPT architecture, the softmax function is commonly used for classification tasks. The softmax function is applied to the output of the final layer of the model. It generates a probability distribution over a set of output classes. The output of the final layer is specifically converted into a set of logits before being normalized with the softmax function. The normalized values obtained from the model can be interpreted as the likelihood or probability that a particular input belongs to each of the output classes. The query, key, and value vectors for each token in the input sequence are frequently calculated using linear functions in the attention mechanism. The output of the multihead attention layer is transformed using them in the feedforward layers as well. The output layer also employs linear functions to forecast the following token in the sequence.
• Pre-training: Pre-training is a key component of the GPT architecture. In pre-training, the model is trained on a large amount of data in an unsupervised manner even before fine-tuning the model for specific tasks like classification and text generation.
• Fine-tuning: Fine-tuning is the process of adapting a pretrained neural network model, such as GPT, to a new task or dataset by further training the model on that task or dataset. Fine-tuning in GPT involves adjusting the parameters of the pre-trained model to optimize performance on a specific downstream task, such as text classification or text generation.
• Language modeling: Language modelling is a key task in the GPT architecture. In the case of GPT, the language modelling task is performed during the pre-training phase of the model. In pre-training, the model is trained based on a large amount of data using a language model objective. It is the task of predicting the next word in sequence based on the previous words. It allows the model to learn relationships between the words and their meaning in the training data.
• Unsupervised learning: Unsupervised learning is an ML algorithm which enables the model to learn form unlabelled data without any human intervention. GPT models use unsupervised learning in the pre-training phase to understand the relationships between the words and their context in the training data.
How do GPT models work?
GPT models work by using a transformer which is a neural network architecture that processes the input sequences of natural language text. The GPT model uses unsupervised learning techniques to pre-train this transformer architecture on a significant amount of text input. The model gains the ability to anticipate the subsequent word in a sequence based on the preceding words during pre-training. Language modelling is the process that enables a model to discover the statistical connections between words and their context in training data. Fig. 5 shows the various stages of GPT operation. The first step entails supervised fine-tuning, the second step involves producing optimal responses to input, and the third step involves proximal policy optimization and reinforcement learning.
The model can be fine-tuned for particular tasks, like text classification or text production, after pre-training. The model is trained on a smaller dataset that is unique to the work at hand during fine-tuning, and the model’s parameters are changed to maximize performance on that task. Fig. 3 shows the general transformer architecture of GPT.
When used for text creation, GPT models create text by anticipating the following word in a series based on the previously created words. Depending on how it has been modified, the model can produce text that is comparable to the input text or that adheres to a certain theme or style. Fig. 4 projects the GPT model’s transformer architecture and input transformations for fine-tuning different tasks."
(b) Conjecture generator (also called the Ramanujan machine named after the Indian mathematician Srinivasa Ramanujan)
In mathematics, a conjecture is a conclusion or a proposition that is proffered on a tentative basis without proof. Some conjectures, such as the Riemann hypothesis proposed around 1859 CE (still a conjecture) or Fermat's Last Theorem proposed around 1637 CE (a conjecture until proven in 1995 by Andrew Wiles), have shaped much of mathematical history as new areas of mathematics are developed in order to prove them. Srinivasa Ramanujan (1887 – 1920) was an Indian mathematician. Though he had almost no formal training in pure mathematics and initially developed his own mathematical research in isolation, he made substantial contributions to mathematics, including solutions to mathematical problems then considered unsolvable. During his short life, Ramanujan independently compiled nearly 3,900 results (mostly identities and equations). Many were completely novel; his original and highly unconventional results have opened entire new areas of work and inspired a vast amount of further research. Of his thousands of results, all but a dozen or two have now been proven correct.
The Ramanujan machine is a specialized software package, developed by a team of scientists at the Israeli Institute of Technology, to discover new formulas in mathematics. According to the scientists: "We wanted to see if we could apply machine learning to something that is very, very basic, so we thought numbers and number theory are very, very basic." (From Wikipedia: Number theory is a branch of pure mathematics devoted primarily to the study of the integers and arithmetic functions. German mathematician Carl Friedrich Gauss (1777–1855) said, "Mathematics is the queen of the sciences—and number theory is the queen of mathematics.")
The machine has produced several conjectures involving some of the most important constants in mathematics like e and π (pi). Some of these conjectures produced by the Ramanujan machine have subsequently been proved true. The others continue to remain as conjectures. The details of the machine were published online on 3 February 2021 in the journal Nature. Below is a public version of the paper prior to actual publication:
The Ramanujan Machine: Automatically Generated Conjectures on Fundamental Constants
